Meine Reise mit ChatGPT, n8n, Claude Code bis OpenClaw – vier Phasen vom Chat zur Agent-Orchestrierung
You can find an english version of this article on Substack and Medium
Das Entwicklungs-Tempo im AI Space verläuft rasant. Schon längere Zeit ist es unübersichtlich geworden und es fällt schwer, die Flut an Ankündigungen und Neuigkeiten von echten Innovationen zu unterscheiden.
Dabei drehen sich die zentralen Fragen immer wieder um dieselben Themen:
- Welche Aufgaben kann AI übernehmen?
- Wie gelingt es, mit Hilfe von AI verlässliche Ergebnisse zu erzielen?
- Welchen Input braucht es dazu?
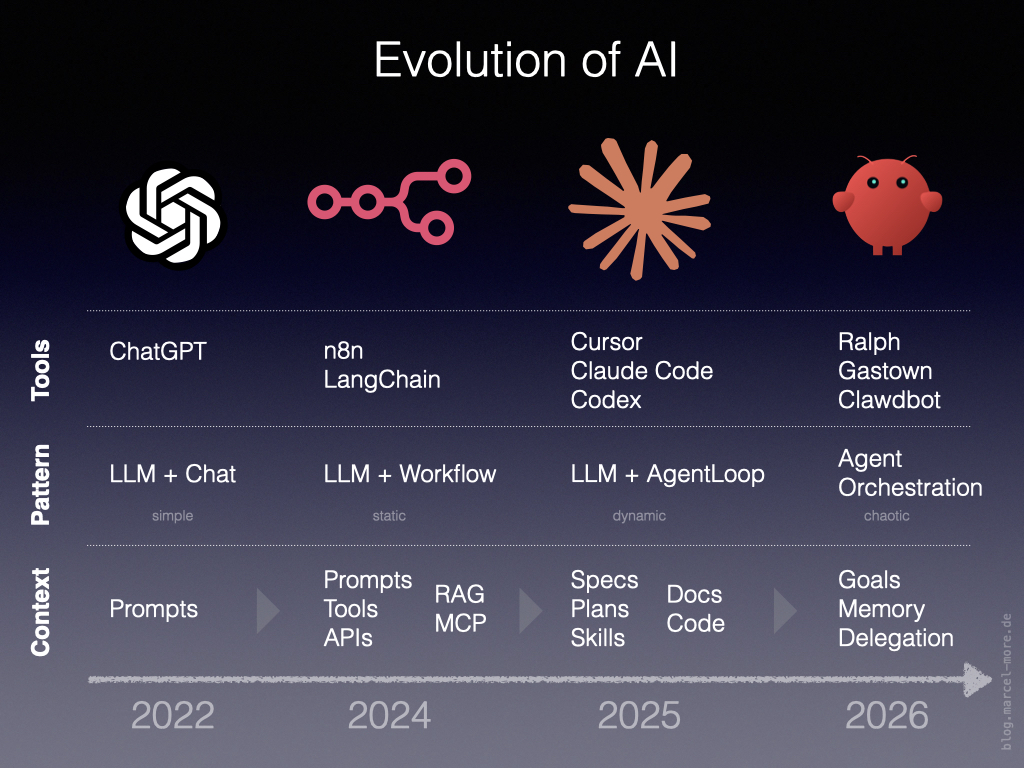
Betrachtet man die Entwicklung der letzten Jahre bei den Tools und deren Funktionsweisen, erkennt man Muster, welche die Qualität der Ergebnisse maßgeblich beeinflussen.
Diese Entwicklung lässt sich gut in vier Phasen einteilen:
Wir schauen uns diese Phasen genauer an, um die Unterschiede zu verstehen und zu sehen, wie und warum jede Phase auf der vorherigen aufbaut.
Die Betrachtung mündet in
Ausgangspunkt ist meine persönliche Reise durch diese Phasen mit Tools wie ChatGPT, n8n, Claude Code bis hin zu OpenClaw. Je mehr ich damit gearbeitet habe, desto klarer wurden mir die Prinzipien, die hinter diesem Wandel stehen.
Der Text erhebt keinen Anspruch auf Vollständigkeit. Er beschreibt die Weiterentwicklung der AI Tools anhand von Beispielen und ausgewählten Methoden.
Phase 1 – AI Chat
Die öffentliche Wahrnehmung von AI begann mit dem Debüt von ChatGPT im Jahr 2022. Erstmals war ein Large Language Model (LLM) für jedermann verfügbar. Das Besondere daran war das Chat-Interface, das sich bis heute für viele AI Anwendungen etabliert hat.
Prompts
Eine neue Kultur-Technik namens „prompten“ entstand. Man teilt der AI mit, was man von ihr wissen möchte oder was sie tun soll. Vergleichbar mit „googeln“ dessen Funktionsweise viele bereits verinnerlicht hatten. Diese Analogie im Bedienkonzept verhalf ChatGPT schnell zum Durchbruch, denn damit war man in der Lage, einen einfachen Zugang zur AI zu nutzen.
Genauso schnell zeigte sich jedoch, dass googeln und prompten teils sehr unterschiedliche Ergebnisse liefern, was Fluch und Segen zugleich ist. Einerseits gehen die Ausgaben von ChatGPT weit über die Ergebnislisten einer Internetsuche hinaus, weil das LLM über ein breites Weltwissen und fundiertes Verständnis von Sprache verfügt. Andererseits sind die Ergebnisse prinzipbedingt völlig unvorhersehbar und führen oft genug auch zu „Halluzinationen“, weil das Modell plausibel klingende Antworten generiert, ohne immer eine verlässliche Quelle zu haben. Daher auch der Begriff „Generative AI“, weil aus einfachen Eingaben stets neue Ausgaben in Textform und inzwischen auch multimedial (Ton, Bild, Video, 3D-Welten) erzeugt werden können.
RAG
Eine Lösung für dieses Problem bestand zunächst in besseren und umfangreicheren Prompts. Bald ging man dazu über, auch eigenen vorherbestimmbaren Content in den Prozess einzubinden. Mit der "Retrieval Augmented Generation" (RAG) entstand eine Möglichkeit, semantisches Wissen aus eigenen Quellen mit den Stärken des Sprachmodells zu verknüpfen.
Dieser Schritt erforderte auf technischer Seite bereits einen koordinierten Prozess für Bereitstellung und Abruf der Informationen, der über das reine Chat-Interface hinaus geht. Die nächste Entwicklungs-Phase begann.
Phase 2 – AI Workflows
Zusätzlich zum Chat-Interface stellen die großen AI Anbieter auch direkte Schnittstellen (APIs) für ihre Modelle zur Verfügung. Damit ist es möglich, die Ein- und Ausgaben über einen programmierten Ablauf zu steuern.
Da es anfangs umständlich war, für jedes Modell und jeden Einsatzzweck eine separate Schnittstelle und einen eigenen Ablauf zu programmieren, entstanden bald neue Tools und Standards, um die zugrunde liegenden Methoden über einen einfacheren Zugang auf einer logischen Abstraktionsschicht bereitzustellen.
Tools und APIs
Tools wie LangChain kombinieren den Zugriff auf LLMs, auf Datenquellen (RAG), auf externe Tools (APIs) und die Steuerung eines flexiblen Ablaufs durch Prompt-Vorlagen und Workflow-Macros. Das Zeitalter der AI Agenten wurde eingeläutet, auch wenn vieles noch nicht dem Idealbild eines wirklich autonomen Agenten entsprach, sondern eher einem mit AI angereicherten Workflow. Anbieter von existierenden Workflow-Automatisierungs-Plattformen sprangen schnell auf diesen Zug auf.
Neben den bekannten Playern wie Zapier oder Make sorgte ein neuer Shooting-Star für Aufsehen: n8n eroberte das Publikum im Sturm, weil es eine sehr einfache Benutzeroberfläche mit der Fähigkeit kombinierte, agentische Abläufe mit zahlreichen externen Schnittstellen und Datenquellen zu verbinden. Die sogenannten "Flows" lassen sich in der Cloud oder auf eigenen Servern ausführen und ermöglichen damit auch einem nicht technischen Anwender, schnell komplexe AI Workflows zu erstellen und zu betreiben.
Die AI Anbieter selbst stellten neben den Chatbots ebenfalls neue Produkte für den Zugriff auf Tools und externe Datenquellen vor. Neben den großen Namen wie OpenAI, Anthropic, Microsoft und Google entstand eine unüberschaubare Vielzahl von spezialisierten neuen Anbietern in diesem Bereich. Das Portfolio der neuen Produkte aus dieser Phase fokussierte sich schwerpunktmäßig auf die Steuerung von agentischen Workflows und die Verbindung mit Werkzeugen für spezifische Einsatzzwecke.
Je komplexer die Einsatzzwecke wurden, desto deutlicher wurde ebenfalls, dass die rein Prompt-basierte Steuerung an ihre Grenzen stößt. Immer ausgefeiltere Verfahren für das "Context-Engineering" machten die Runde.
Context-Engineering und MCP
Mit der Veröffentlichung des "Model Context Protocol" (MCP) von Anthropic entstand ein offener Standard für die Ansteuerung von Tools, der schnell von vielen Anbietern übernommen wurde. MCP verbindet drei wichtige Zutaten für die Steuerung des AI Workflows: Prompts, Tools, Datenquellen. Diese können nun in einheitlicher Weise kombiniert und für einzelne Anwendungszwecke verpackt und bereitgestellt werden.
Claude und ChatGPT erweiterten ihre Chatbots mit Features wie "Advanced Data Analysis", "Code Interpreter", "Canvas" und "Artifacts". Diese sind in der Lage, in einem separaten Bereich innerhalb des Chat-Fensters Code zu generieren und auszuführen. Die Ausgabe geht über reine Text-Antworten hinaus, stattdessen werden echte Ergebnisse angezeigt. Damit rückten auch hier Workflow-Features und Code stärker in den Fokus. Später kamen direkte Tool-Schnittstellen und MCP dazu.
Im Coding Bereich entstanden Tools wie Cursor oder Windsurf, die anfangs mit intelligenter Code-Vervollständigung die Entwicklung von Programmcode beschleunigten. Später kamen Prompt-Vorlagen auf System- und Projekt-Ebene dazu, um die LLMs auf spezifischere Anwendungszwecke zu briefen.
Reasoning als Zutat für Agenten jenseits von Workflows
Auch die Entwicklung der Large Language Modelle selbst ging weiter. Methoden wie "Mixture of Experts" (MoE), "Reasoning Models" und "Chain of Thought" erweitern die Möglichkeiten der Frontier-Modelle und bilden die Grundlage für immer mehr agentische Fähigkeiten wie z.B. "Deep Research". Feedback-Schleifen mit und ohne Benutzereinbindung steigern die Leistungsfähigkeit. Insbesondere bei Code-Generierung gab es enorme Fortschritte, weil hier die sprachliche Genauigkeit und inhärente Logik sehr klar umrissen ist.
Viele dieser Methoden bauten aber nach wie vor auf statischen Prompts oder generischen Workflows auf. Mit der Entstehung von immer dynamischeren Methoden des Context-Engineering wurde die nächste Phase eingeläutet.
Phase 3 – AI Agents
Mit Replit, Lovable oder auch GitHub Spark entstand eine neue Methode der agentischen AI im Coding Bereich. Ausgehend von einem Prompt, der eher einer Zielbeschreibung entspricht, generiert ein Sprachmodell zunächst ein detailliertes Anforderungsdokument (PRD). Aus diesem wird ein Plan mit einzelnen Schritten abgeleitet, den ein Coding-Agent dann umsetzt.
Spec Driven Development
Je nach Ausprägung des Tools kann der Benutzer in diesen Prozess eingreifen, indem er zum Beispiel das Anforderungsdokument überarbeitet und dem Coding-Agenten damit sehr explizite Beschreibungen des gewünschten Ziel-Zustands und der Umsetzungsschritte liefert. Die Erstellung des Prompts selbst wird nun durch einen strukturierten Prozess geleitet. Ergänzend liefert das Sprachmodell Hintergrundwissen zu Best Practices und Coding Patterns. Das neue Pattern für immer autonomere Agenten lautet nun „Plan → Act → Verify“. Der Benutzer wird vom Programmierer zum Architekten bzw. Produkt-Manager und agiert auf einer High-Level Ebene mit dem Tool. Um die Ausführung der Details kümmert sich das AI Modell innerhalb einer agentischen Schleife. Die vorab erstellte Spezifikation mitsamt Erfolgskriterien entscheidet maßgeblich über die Qualität der Ergebnisse.
CLI-Tools
Um die Schnittstelle für das Coding näher an den Benutzer zu bringen, entstand eine neue Kategorie von agentischen Tools auf dem Command Line Interface (CLI). Dies ermöglicht eine bessere Integration in vorhandene Entwicklungsumgebungen (IDEs) und auch die direkte Kommunikation mit dem Agenten in der gleichen Umgebung, wo Zugang zu Code, Tools und Betriebssystem möglich ist. Die AI Agenten lösen sich komplett aus dem bisherigen Chat-Interface und bekommen nun Zugriff auf Systemebene des Rechners auf dem sie eingesetzt werden. Das ist ein kompletter aber konsequenter Paradigmen-Wechsel.
Agentic Loop
Der Shooting-Star in dieser Kategorie ist Claude Code, welches als eines der ersten Tools die "Agentic Loop" weiter perfektioniert und mit starken LLM Modellen kombiniert hat. Zusammen mit dem Zugriff auf alle lokalen Dokumente, CLI-Tools und externen MCPs bietet dies eine extrem leistungsfähige Basis für eine dynamische Orchestrierung agentischer Abläufe.
Auch die anderen großen Anbieter zogen nach, mit Codex (OpenAI), Gemini CLI (Google), GitHub CLI (Microsoft) und vielen weiteren Spezial-Tools wie OpenCode, Amp, Warp, u.a. ist diese Kategorie inzwischen eine feste Größe in der AI Landschaft geworden.
Bereits existierende Tools aus dem IDE-Umfeld wie Cursor integrierten diesen Ansatz und entwickelten ihn teils um eigene Features weiter, wie Browser-Testing oder Multi-Agenten-Orchestrierung.
Darüber hinaus etablierten sich neue Pattern für den Einsatz dieser Technik. Mit hierarchischen Prompt-Dateien (AGENTS.md oder CLAUDE.md), Slash-Commands, Hooks, Subagents und Skills entstanden immer neue Verfeinerungen, um die existierenden Ansätze zum Context-Engineering und Spec Driven Development zu erweitern.
Skills
Hervorzuheben sind hier insbesondere die sogenannten "Skills", die ebenfalls von Anthropic etabliert wurden. Diese stellen eine neue Art der Konfektionierung für Fähigkeiten von Agenten dar. Ähnlich wie ein MCP können hier mehrere Komponenten zusammen in einer Beschreibung verpackt und auch für andere Benutzer und Systeme weiter verteilt werden. Da diese Skills aber nur bei Bedarf geladen und verarbeitet werden, entlastet dies das Kontextfenster und schafft einen noch flexibleren Ansatz für umfangreichen und dynamischen Kontext.
Ein Skill enthält zunächst eine Beschreibung in natürlicher Sprache, sozusagen einen spezifischen System-Prompt für die jeweilige Aufgabe. Zusätzlich können weitere Dokumente mit Beschreibungen, Beispielen oder Daten enthalten sein. Sowie dedizierter Code für die Ausführung von Workflows in Form von Bash, Python, JavaScript oder anderen vom Agent ausführbaren Sprachen. Damit lassen sich sowohl lokale als auch externe Tools und APIs orchestrieren. Auch MCPs können eingebunden werden. Oft lässt sich aber mit einem reinen Skill auf Basis von Anweisungen, Code und API-Zugriffen eine sehr viel schlankere Implementierung einer Aufgabe abbilden.
Autonome Agents
Durch die Kombination aller genannten Fähigkeiten entstehen flexible und teils sehr wirkmächtige Agents. Das Zusammenwirken aus vorgefertigten Beschreibungen, Best Practices aus dem Sprachmodell und Zugriffsmöglichkeiten auf Dokumente, Daten und Tools innerhalb einer klaren Feedback Schleife lassen einen Agent wie einen Mitarbeiter autonom an einer Aufgabe arbeiten.
Eine wichtige Grundlage ist die klare Strukturierung der Vorgehensweise in mehreren aufeinander aufbauenden Schritten:
- Beschreibung der Aufgabe (Specs)
- Erstellung eines Ablaufplans
- Ausführung von Aufgaben
- Zugriff auf Tools und Daten
- Kontrolle der Ergebnisse
- Feststellen des Zielzustands
Der Kontext für das LLM wird hierbei iterativ über mehrere Stufen dynamisch erzeugt und immer wieder mit vorgegebenen Zuständen abgeglichen.
Auch die dynamische Erweiterung des Funktionsumfangs für eine Aufgabe ist Teil des Ablaufs. Steht ein Tool für einen Ausführungsschritt nicht unmittelbar zur Verfügung, ist der Agent in der Lage, dieses Tool kurzerhand selbst zu programmieren und direkt auszuführen. Durch sein umfangreiches Vorwissen aus dem LLM ist er dabei inhaltlich wie methodisch autonom unterwegs. Entstehen Fehler oder lose Enden, kann der Agent dies selbstständig feststellen und oft genug auch durch mehrfache Versuche selbstständig beheben.
Damit dies für den Benutzer überschaubar bleibt, kann er den Agenten in unterschiedlichen Betriebsmodi starten:
- ausschließlich planen
- planen und ausführen nach Rückmeldung+Bestätigung
- völlig autonome Ausführung
Macht und Verantwortung
Mit der autonomen Ausführung entstehen neue Chancen und Risiken. Um die Risiken zu minimieren, hilft es in erster Linie die Spezifikationen und Pläne zu Beginn des Ablaufs möglichst umfangreich und genau zu verfassen. Hier sollte der eigentliche Arbeitsschwerpunkt des Benutzers liegen. Je besser die Vorgaben, desto vorhersehbarer die Ergebnisse. Die Bereitstellung gut strukturierter und sauberer Daten ist, je nach Anwendungsfall, ebenfalls eine Grundvoraussetzung für exzellente Ergebnisse.
Zusätzlich können Einschränkungen bei den Rechten von ausführbaren Tools sowie klar umrissene Arbeitsumgebungen (Sandboxes) helfen, den möglichen Impact zu steuern. Regelmäßige Snapshots der erzeugten Ergebnisse in einem git für ein strukturiertes Rollback auf frühere Zustände sind ratsam.
Je mehr Freiheitsgrade ein Agent hat, desto unkontrollierbarer sind manchmal auch die Fehler, wenn er aufgrund fehlerhafter Annahmen irgendwo falsch abgebogen ist (Agentic Drift). Daher ist die Kontrolle der Ergebnisse durch den Benutzer ein wichtiges Steuerungsinstrument. Im Bereich des Codings gibt mit Pull-Requests (PRs) und den damit verbundenen Code-Reviews bereits etablierte Workflows, um grundlegende Arbeitsschritte in umfangreicheren Projekten zu strukturieren.
Auch diese Schritte werden z.T. bereits durch eigene Agenten mit spezifischen Skills automatisiert. Warum einem Agent vertrauen, wenn ein zweiter Agent ihn kontrollieren kann?
Damit sind wir bei der nächsten Phase der AI Evolution im Jahr 2026 angekommen.
Phase 4 – Agent Orchestration
Neue Konzepte wie "Ralph Wiggum" oder "Gastown" stehen exemplarisch für eine weitere Optimierungsstufe des Context-Engineering. Während "Ralph" eher darauf abzielt, die Überprüfungskriterien und "Aus-Fehlern-lernen"-Fähigkeiten des Ablaufs zu verbessern, verfolgt "Gastown" einen anderen Ansatz. Hier werden einfach zahlreiche Instanzen parallel mit der gleichen Aufgabe betraut und am Ende entscheidet ein Schiedsrichter, wer die bessere Lösung gefunden hat. Eine Art Wettkampf um die beste Lösung für das vorgegebene Ziel. Eine zusätzliche Verfeinerung besteht darin, den Lösungsweg vorab in kleinere Schritte zu zerlegen, die sinnvoll aufeinander aufbauen. Sind die ersten Bausteine für den Lösungsweg vorhanden, können weitere Agenten darauf aufbauen, und damit auch komplexere Aufgaben sinnvoll zu Ende bringen. Hier tut sich eine Option für mehr Parallelverarbeitung auf, weil Teilaufgaben autonom vervollständigt werden.
Der einzige Haken: Diese Strategien kommen mit einem Preisschild. Dadurch dass Versuche mehrfach wiederholt oder parallel von mehreren Agenten ausgeführt werden, werden auch immer mehr Tokens verbraucht. Immer mehr Rechenleistung wird benötigt, der Energieverbrauch steigt.
Zugleich steigt die Ausführungszeit an. Die autonomen Agenten arbeiten teils Stunden oder Tage an der Lösung einer Aufgabe. Dies ist jedoch kein Bug sondern ein Feature, denn entsprechend groß und komplex sind inzwischen die Aufgaben, die mit diesen Methoden lösbar sind. Einige beachtliche Erfolge machen inzwischen die Runde. So hat beispielsweise Cursor in einem Demo-Projekt eine komplette Browser-Engine mit Millionen Codezeilen von Grund auf neu entwickelt innerhalb weniger Tage. Auch "Claude Cowork" – ein neues Produkt von Anthropic – wurde innerhalb weniger Tage von "Claude Code" entwickelt. Ergebnisse, die noch vor 1-2 Jahren völlig undenkbar schienen.
Der aktuelle Hype zu "Clawdbot" – inzwischen umbenannt zunächst zu "Moltbot" und nun zu "OpenClaw" – speist sich aus den beschriebenen Zutaten. OpenClaw hat die Orchestrierungs-Strategien verfeinert und weiter ausgebaut. Der Bot ist in der Lage, dynamisch weitere Skills nachzuladen und neue zu erzeugen. Zudem hat er ein persistentes Gedächtnis und lernt so mit der Zeit, sich auf bestimmte Dinge zu fokussieren. Über täglich gesteuerte Schleifen holt er sich neuen Kontext aus dem Internet und interagiert proaktiv mit seinem Benutzer. Sobald dieser Aufgaben an ihn delegiert, handelt der Bot autonom und interagiert auch mit externen Personen, externen Wissensquellen und anderen Bots. Ein eigenes Bot-Forum namens "Moltbook" sorgt derzeit für Aufsehen, weil es ausschließlich dazu dient, dass sich autonome Bots untereinander austauschen und unter anderem Erfahrungswissen miteinander teilen. Auch dies ist eine Art von Context-Engineering-Pattern. Jedoch eines, das weit über die bisherigen konzeptionellen Beschränkungen von lokalen Agents hinaus geht.
Update: Mit "Antfarm" ist aktuell ein neues Open-Source-Tool erschienen, das die Ansätze von „Ralph“ und „Gastown“ in einem flexibel konfigurierbaren Framework vereint und sich einfach auf „OpenClaw“ installieren lässt. Es verspricht „Ein Agenten-Team auf Knopfdruck“ zu erstellen, welches völlig autonom Software entwickeln kann.
Erfolgsfaktoren
Schaut man sich die Weiterentwicklung der AI Tools und ihrer zugrunde liegenden Pattern rückblickend an, so kann man einige kritische Erfolgsfaktoren identifizieren. Dabei geht es nicht so sehr um einzelne Features von AI Tools, sondern um generelle Strategien auf einer abstrakteren Ebene.
Diese lassen sich auf folgende Faktoren herunter brechen:
- Context
- Code
- Loops
Besserer Context und Code
Ein wesentlicher Erfolgsfaktor ist immer feiner granulierter Context, der hierarchisch organisiert und zur Laufzeit dynamisch an das Sprachmodell ausgeliefert wird. Angereichert um ebenfalls zur Laufzeit generierten Code, der dazu dient, Abkürzungen zu finden, verlässliche Tools zu erzeugen und weiteren Context aus externen Quellen hinzuzufügen.
Damit ist das Context-Engineering auf einem neuen Level angekommen:
Input = Sprache, Code und Daten
Output = Sprache, Code und Daten
Die Grenzen zwischen Code und Sprache verschwimmen zunehmend. Ein Bonmot von Andrej Karpathy beschreibt es so: "The hottest new programming language is English"
Benutzer geben Anweisung in Form von Zielen und Erfolgskriterien. Agenten handeln autonom in Schwärmen und kontrollieren und korrigieren sich selbstständig, bis das vorgegebene Ziel erreicht ist.
Komplexere Patterns
Die Komplexität der Pattern hat sich von einfachen, statischen über dynamische bis zu chaotischen Umsetzungsschritten weiter entwickelt. Das eigentlich paradoxe dabei:
Je einfacher die Input-Pattern zu Beginn der AI Evolution, desto unberechenbarer waren die Ergebnisse (Halluzinationen).
Je chaotischer die Input-Pattern in der fortgeschrittenen Stufe, desto deterministischer wirken die Ergebnisse. Weil in der Summe der Aktionen über viele Schleifen hinweg ein klares Ziel verfolgt und somit divergente Ergebnisse iterativ geglättet werden können.
Hier wird ein weiteres Muster erkennbar. Waren es zunächst einfache Prompts in Textform, aus denen die Anweisungen für LLMs bestanden, so sind es nun hierarchisch organisierte Anweisungen aus Text und Code, die in mehrfach geschachtelten Schleifen verarbeitet werden.
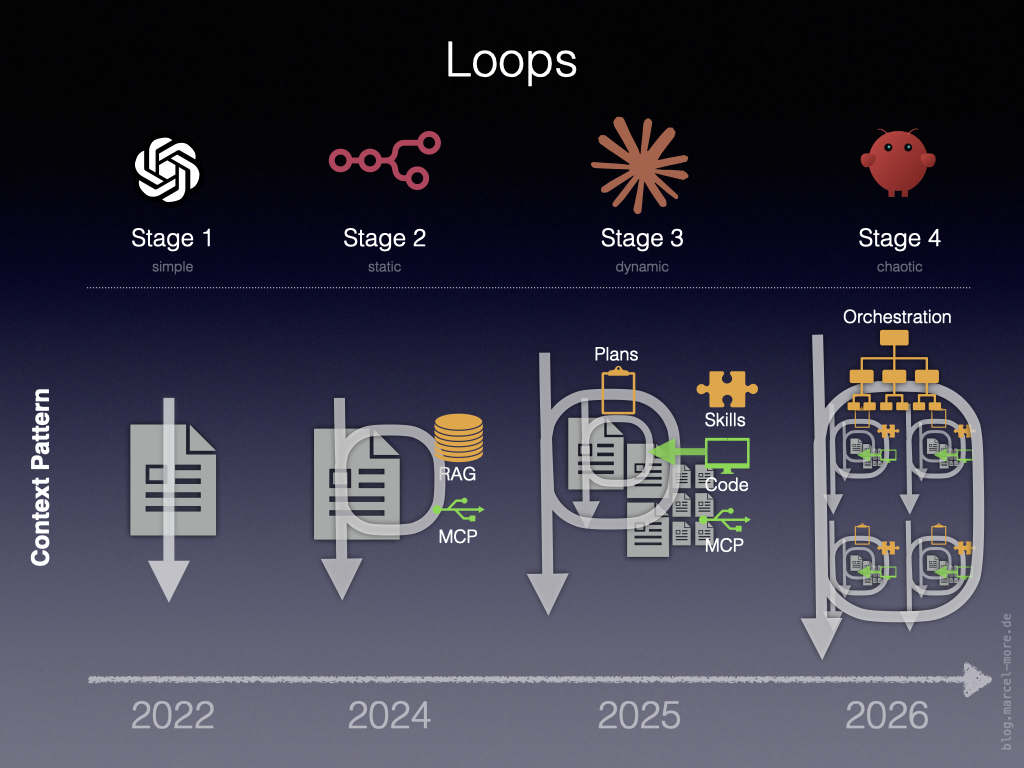
Hulahoop – Schleife um Schleife
Jede Evolutionsstufe hat eine weitere Schleifen-Ebene hinzugefügt.
Level 1-2: Reasoning Loop
Level 2-3: Agentic Loop
Level 3-4: Ralph Loop / Orchestration Loop
Diese Schleifen sind ineinander verschachtelt und dienen dazu, die eigentlich unvorhersagbaren Ergebnisse des LLM stufenweise auf einen definierten Zielzustand hin zu verdichten.
Das Pattern baut direkt auf den verfeinerten Context-Engineering Strategien auf. Die Möglichkeit, zur Laufzeit dynamisch Code zu generieren ermöglicht es, die Context-Häppchen deterministisch mit den Zwischenergebnissen abzugleichen und den gesamten Prozess in Teilschritten zu steuern.
Dazu kommen weitere Pattern wie Debating, Shuffling, Goal-Matching, um das Risiko von festgefahrenen Schleifen zu durchbrechen und ausreichend Varianz in den Gesamt-Prozess einzusteuern. Frühe Agentic-Loops neigten dazu, bei falschen Entscheidung, sich wiederholende Fehler zu produzieren. Durch bessere Strategien auf der Orchestrierungs-Ebene lassen sich diese Effekte minimieren.
Moderne Bots wie OpenClaw fügen mit Heartbeat weitere Loops jenseits der eigentlichen Tasks hinzu. Sozusagen ein Idle-State für den Agenten, der ihn fortlaufend handlungsbereit macht, auch ohne Benutzer-Interaktion.
Auch auf Modell-Ebene gibt es neue Konzepte wie Recursive Language Models, mit denen das Modell den Kontext effizienter verarbeiten kann. Die Rekursion ist sozusagen eine bedingte Schleife, mit welcher das Modell vorab eine optimale Route auch durch umfangreiche Kontextmengen findet.
Fazit
Es ist zunächst wichtig zu verstehen, dass diese Weiterentwicklung nur in einer logischen Abfolge möglich war. Eine Stufe baut auf den Erfolgen und Misserfolgen der vorigen Stufe auf. Dadurch entsteht Fortschritt aber auch eine Menge Widersprüche.
Deutlich wird dies in Diskussionen oder rückwärtsgewandten Studien, die z.T. die Sinnhaftigkeit von AI Anwendungen grundsätzlich in Frage stellen, ausgehend von Ergebnissen die auf einer früheren Stufe gewonnen wurden. Dazu kommt die rasante Entwicklung im gesamten AI Bereich, einhergehend mit vielen Einzelkonzepten und Buzzwords, die es einerseits schwierig machen, den Überblick zu behalten und ein Verständnis für einzelne Ansätze zu gewinnen. Andererseits liegt darin auch eine Hürde, sich darüber in einer klaren Sprache mit einheitlichen Bedeutungszuweisungen auszutauschen.
Daher ist es hilfreich, sich von der Sicht auf einzelne Anbieter, Tools oder Features zu lösen und zu versuchen, die Dinge auf einer abstrakteren Ebene zu betrachten.
Was dabei unter anderem deutlich wird, ist einerseits die immer weiter fortschreitende Verfeinerung von Strategien. Anderseits aber auch die zunehmende Komplexität und der steigende Ressourcenverbrauch, um letztlich oft einfach erscheinende Dinge zu lösen. Dabei gilt es zu unterscheiden, welche Art Aufgaben man der AI stellt und mit welcher Strategie und welchem Aufwand diese möglicherweise lösbar ist. Auch dies oft noch ein Dilemma – mit Kanonen auf Spatzen schießen macht keinen Sinn, wenn das Ergebnis teuer erkauft wird. Auf der anderen Seite bewegen wir uns mehr und mehr in Aufgabenfelder, die ohne die Hilfe von AI nur schwer oder überhaupt nicht lösbar scheinen.
Denkt man die oben beschrieben Schlussfolgerungen weiter, stellt sich zwangsläufig die Frage, was als nächstes kommen mag.
Die nächste Stufe
Naheliegend ist, dass mit zunehmender Komplexität auch neue Probleme entstehen. Daher könnte es hilfreich sein, die bereits gewonnenen Erkenntnisse und identifizierten Strategien in einer nächsten Stufe neu zu kombinieren. Mit dem Ziel, Komplexität zu reduzieren und einfache Pattern zu etablieren, die sich gegenseitig unterstützen und verstärken.
Wir haben bereits festgestellt, dass immer mehr verschachtelte Schleifen unter den genannten Bedingungen einen immer besseren Fokus produzieren. Was würde passieren, wenn wir diesen Ansatz generalisieren? Nicht einfach noch eine nächste Schleife mit neuen Pattern oben drüber stülpen, sondern eine endlose Schleife als Grundprinzip in den gesamten Prozess einbauen.
Wir haben ebenfalls festgestellt, dass Context-Bereitstellung und die Agent-Loop eng miteinander zusammen hängen. Ein wichtiges Wechselspiel besteht in der häppchenweise Anreicherung von Context durch Tools in Form von Code. Die derzeitige Brücke dafür sind Skills, welche die Agent-Prompts mit Tools und Datenquellen verpackt bereit stellen. So gesehen sind auch Skills nur weitere Context-Quellen. Auch ein Gedächtnis in Form aller bisherigen Ein- und Ausgaben ist eine Form von Context, jedoch mit einer höheren Gewichtung, weil hier die Ziele des Nutzers und die gemachten Erfahrungen codiert werden.
Die effizientere Verwaltung sowohl von aktivem Context für eine Aufgabe, als auch passivem Context in Form von gespeicherten Erinnerungen, ist eine zentrale Aufgabe, die es zu lösen gilt.
Zwar haben LLMs bislang immer größere Kontextfenster erhalten, aber dem sind prinzipbedingt bislang Grenzen gesetzt. Eine Lösung liegt in der Agent-Loop, welche dafür sorgt, dass die begrenzten Kontextfenster mit immer neuen fein granulierten Teilaufgaben bestückt werden. Für die Orchestrierung dieser Teilaufgaben braucht es Ziele, Pläne und Abgleichkriterien, welche ebenfalls als Context in das Gesamtsystem eingehen.
Somit nähern wir uns einem Gebilde, das alle diese Zutaten inhärent in sich vereint. Wenn Anweisungen, Wissen, Gedächtnis und Lösungsstrategien alle Teil der selben Context-Menge werden, besteht die Aussicht, dass dieses System sich selbst organisiert, dazu lernt und potentiell mit jeder weiteren Schleife neue Erkenntnisse gewinnt.
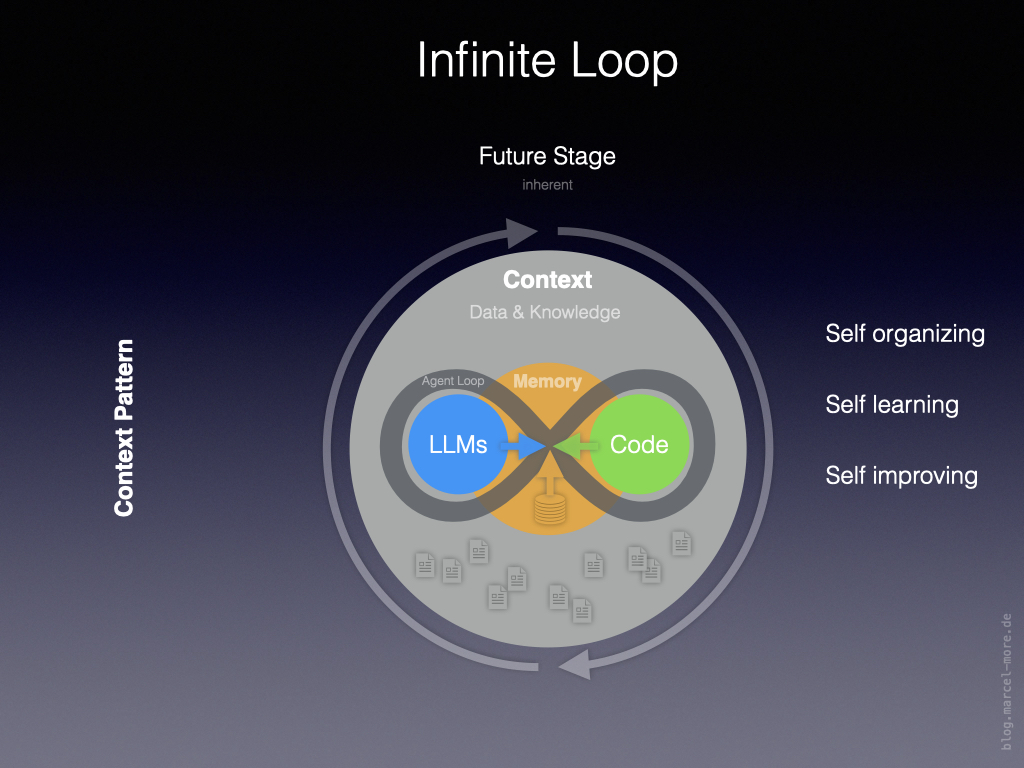
Infinite Loop
Im nächsten Schaubild sind die genannten Zutaten in einem inhärenten System untergebracht.
Die Architektur stützt sich auf folgende Elemente:
Äußerer Kreis = Data & Knowledge
Hier findet die klassische Context-Verarbeitung statt, inklusive Anbindung von Datenquellen. Also das was bislang Prompts, Skills, MCPs und APIs erfüllen.
Innerer Kreis = persistent Memory
Hier kommt ein zusätzlicher Context-Layer ins Spiel, der eine persistente Schicht von Erinnerungen über vergangene Interaktionen, explizit verankertes Wissen und Meta-Informationen zur Steuerung der Verarbeitung enthält.
Agent-Loop = verbindet LLMs, Code, Memory mit dem Context
Die Agent-Loop entspricht der Verarbeitungsschleife für spezifische Tasks, wie zuvor in Stufe 3 beschrieben. Der Agent nutzt Code, um den Verarbeitungsprozess zu optimieren und neue Aktionen ausführen zu können.
Heartbeat-Loop = äußere Schleife
Die äußere Schleife hält das System am laufen. Neben dem kontinuierlichen Triggern der Agent-Loop versorgt sie den Context mit neuem Input, Output und externen Daten und reichert so das Systemwissen an. Denkbar wären auch Input über Sensorik (damit das System seinen eigenen Zustand und den seiner Umgebung erfassen kann) und Updates über neues Weltwissen (welches bislang über das Training der LLMs verfügbar gemacht wird).
Das Ganze verbunden mit der Fähigkeit, Dinge neu zu ordnen und veralteten Context zu vergessen, damit sich das System auf gesunde Weise weiter entwickelt.
Zwar kann ich nicht sagen, wie sich ein solches System konkret bauen lässt. Potentiell lässt sich aber erahnen, dass es mit den beschriebenen Eigenschaften in der Lage wäre, eine neue Stufe der zuvor beschriebenen AI Evolution zu erklimmen.
Epilog
Vielleicht ist es eine unendliche Schleife, welche uns zur allgemeinen künstlichen Intelligenz (AGI) bringt? Ein unendlicher Strom an Context, der in unendlichen Wiederholungen destilliert und verdichtet wird, bis das Ergebnis erreicht ist.
Was wird am Ende dabei herauskommen…
42 ?
Vielleicht haben wir dafür dann unendlich viele Tokens und alle Energie der Welt verbraucht, um das zu berechnen.
Egal – lasst es uns herausfinden!